
前端性能优化小扎
最近做完了 DDYQ 这个项目,这是一个基于手机微信端端 APP 应用(也通过套壳端方式运行在 Android 上),为了节省可怜端服务器资源以及回应运营吐槽打开速度慢,我跟后端一起针对性能做了不少优化,有了新的认识,虽然缺乏详细数据的支持(并没有做性能监听),我们主要基于资源压缩和网络延迟考量(白屏时间和首屏时间)。再加上之前针对访问量比较多的大客户店铺的性能优化经验,由于本人并不参与后端开发,因此纯后端的性能优化并没有深刻的认识,按下不谈,主要还是针对前端开发做一个总结。
HTTP 部分
这是一般性能优化的大头,尤其是对于轻应用而言,手机端的浏览器性能并不会成为瓶颈,往往主要还是受限于手机网络巨大的延迟。我们在实践中并没有完全使用所有的优化,而是有侧重点地考虑多种因素和成本。现在来说一下我当初考虑到的点都有哪些(下面几个小节其实相互有交集)
HTTP 链接池分析
第一个针对的点就是HTTP链接池——为保证链接质量和服务器压力,一般浏览器对同一个域名对并发请求会有一个数量上对限制,一般是 4~6 个并发。一般针对这个,我们考虑的是 CDN 分离静态资源:使用 CDN 有几个好处:
- 分散了域名,突破了浏览器对并发链接数量对限制
- 可以对资源进行缓存,提高了服务器的响应速度
- CDN 一般提供分布式存储,使得物理网络的距离缩小,减少代理转发和路由延迟
- 减少了 Cookie 的携带,同时主服务器也不会接受到静态资源的请求
在主题开发中,我们确实是使用了 CDN 进行域名分散,因为静态资源的占比会比较高,用户可能会使用大量的图片进行店铺装修,使用 CDN 有利于减轻主服务器的压力。但是在 DDYQ 中,最终并没有进行 CDN 分发,这里考虑了这么几个因素:
开发成本
CDN 分发需要进行额外的资源部署(当然,这成本微乎其微)应用体量
不同于店铺,DDYQ 的体量很小,在优化即使是全新加载,主要资源网络占用也只有 300K,配合后续的缓存策略和持久链接,CDN 对网络性能的影响百分比在个位数级别用户群体
这里有一个很关键的决策点是,应用本身只针对移动群体。我们知道,移动网络的瓶颈其实不在于带宽而在于延迟(至少在 4G 普及后,加载一个不到 1M 的网页,带宽的影响没想象中大)。另外,DDYQ 全站启用了 HTTPS,域名收敛(即减少请求池中域名的数量)后可以节省 DNS 查找和 SSL 握手/TCP 握手带来的巨大的延迟开销用户体量
与店铺系统不同,DDYQ 的用户体量目前还比较小,很多时候服务器只需要处理千级并发,因此在处理 SSL 加密解密和资源请求等开销上,服务器(有效利用Node的高并发,数据库读写分离与 Redis)的压力还算比较小
综上,针对链接池的优化,我们还是重点考虑了网络延迟对移动用户带来的影响为主,但理解其他因素的影响也有助于选取更加合适的策略
HTTP 头部优化
我们知道,HTTP 是无状态的,为保证记录用户的登录状态,后台会设置一个 HTTPOnly 的 Cookie 配合服务器 Session 保持认证,这个 Cookie 对浏览器端是半透明的(前端并不能读写),而且每次与服务器交互都会带上这个 Cookie,因此 Cookie 数量越多,HTTP 头就越大,这自然会导致数据包的增大。
在没有启用 SPDY/HTTP 2.0 的情况下,一般只有几种方式压缩 HTTP 头部(其实只是针对 Cookie):
- 尽量只使用简单链接(GET 和 POST)减少头部额外信息
- 尽量减少 Cookie 携带的字符串,一般而言这个比较不实用
- 使用 CDN:跨域访问出于安全的考量,并不会携带 Cookie
其实对于 HTTP 头部,能做的事情比较有限(近似认为只有 CDN 分离),但我们至少可以期待一下即将到来的 HTTP 2.0,这可是 Web 开发者的一个盛宴
HTTP 资源优化
前面提到了 HTTP 的优化包括提高并发下载效率,减少重复传输,但其实对传输性能提升的影响不是最主要的。可以想象,HTTP 就好像是快递公司,数据包相当于一个个快递包裹,压缩头部其实类似于减轻运输车辆的重量,启用 CDN 相当于分别使用多条高速公路避免拥堵(其实也减少运输距离),启用持久链接则相当于不用每辆车都重新规划路线(减少握手,类似直接跟随前面车辆),启用 HTTP 2.0/SPDY 则相当于直接开通一条专线铁路。可以看到,最快最稳定当然是开专线,但成本太高,现阶段不太可能。那么其他的方法都是不错的选择,不过我们不应该忽略,最核心的应该是减少包裹的数量和重量。
这里所说的资源优化,是指使用更小的数据包达到使用大数据包的用户体验,这里有一些共识:
- 启用 Gzip 压缩,这个是所有浏览器和服务器都会使用的,因此没啥好说的
合并请求,减少握手次数和网络延迟
这里主要是指合并脚本和图片,比如常用的雪碧图,就是为了减少额外的 TCP/SSL 握手而出现的技术,我们并没有使用雪碧图(因为应用的图片相对较少较小)而使用了样式内联的 Base64 编码,同时使用了 webpack 进行了模块化开发最终将脚本和样式合并成一个单文件引入。在这里需要注意,合并资源不是简单地把所有同类型的资源集中在一起(这常会导致单资源体积过大,如在单页应用中单一 JS 过大会导致首屏时间过长,而应该考虑代码分割),而是根据需要进行适当的资源数量区分压缩混淆脚本和样式,减少无用信息加大数据包体积
这里一般而言就是使用CSSminify和UglyfyJS去除代码的注释,局部变量替换等(其实在 Gzip 的存在下,更多是删除无效的信息如注释。其他混淆对体积减小并不明显)使用 Ajax 传输核心资源并使用脚本拼接,而非通过服务器生成完整页面传送
这里有一个对比,在店铺主题系统中,我们的页面考虑到 SEO 优化,基本上都是通过 Liquid 模版引擎 来动态生成店铺信息,这样会有一个问题,那就是服务器每次被访问均需要动态渲染出完整的 HTML,这样不仅对服务器的计算压力大(这里其实提供了缓存策略,提供页面的缓存而不是每次均要访问引擎服务器),而且在传输的时候由于是完整的 HTML,体积也相对会大一些。
而在 DDYQ 这个移动应用中,考虑到并不需要进行 SEO,我们使用了单页应用的开发方式(SPA),因此服务器并不需要承担计算的压力(如果这里把静态资源放在 CDN,基本就只承担 Ajax 的压力),而后续访问中由于缓存策略,极大地减少了 HTTP 流量
- 使用最合适的图片和多媒体资源
这里其实道理很明显,不同的媒体格式的体积是不一样的。在移动 Web 中,我们没必要使用分辨率巨大的 4K 视频,因为用户体验的提升不明显,对于图片也是,jpeg 格式和 png 在不同的适应场景在同样的用户体验中,其大小是不一样的。一般建议简单的图片使用 png。还有就是只针对 Retina 屏幕才使用高清素材(通过媒体查询判别)
最优缓存策略
在我们项目中,这是最重要与常见的 HTTP 优化策略,前面说到,静态资源可以启用 CDN 缓存优化,可以通过 CDN 的优点加快访问并且减小服务器压力,这里也会针对 CDN 说明一下更进一步的性能优化。
我们知道第一次访问页面的时候浏览器会根据需要缓存一些静态资源,如脚本和样式表,这样第二次的时候再访问同一个页面(如果页面无任何改变)就可以直接使用缓存而无需再次向服务器请求了。我们的关注点其实是放在如何告诉浏览器需要更新缓存与否。
首先,一般不应该让浏览器缓存 HTML,因为 HTML 的内容直接指示着资源的引用,也就是相当于一个入口,试想,入口一直原来的旧文件,引用资源也就谈不上更新可言了,所以除非特殊奇怪的情况,否则 HTML 不应该使用任何缓存机制
这里发生了一件真实的事情,在 DDYQ 第一次优化的时候,我们指定了 HTTP 缓存头,但是发现后面更新活动的时候发现,线上并没有任何改变,后面查找原因才知道后端不小心也把首页 HTML 做成永久缓存了
关于缓存更新机制,其实如果分开讲解会比较复杂与繁琐,这里我借用网络上的一张图来说明一下: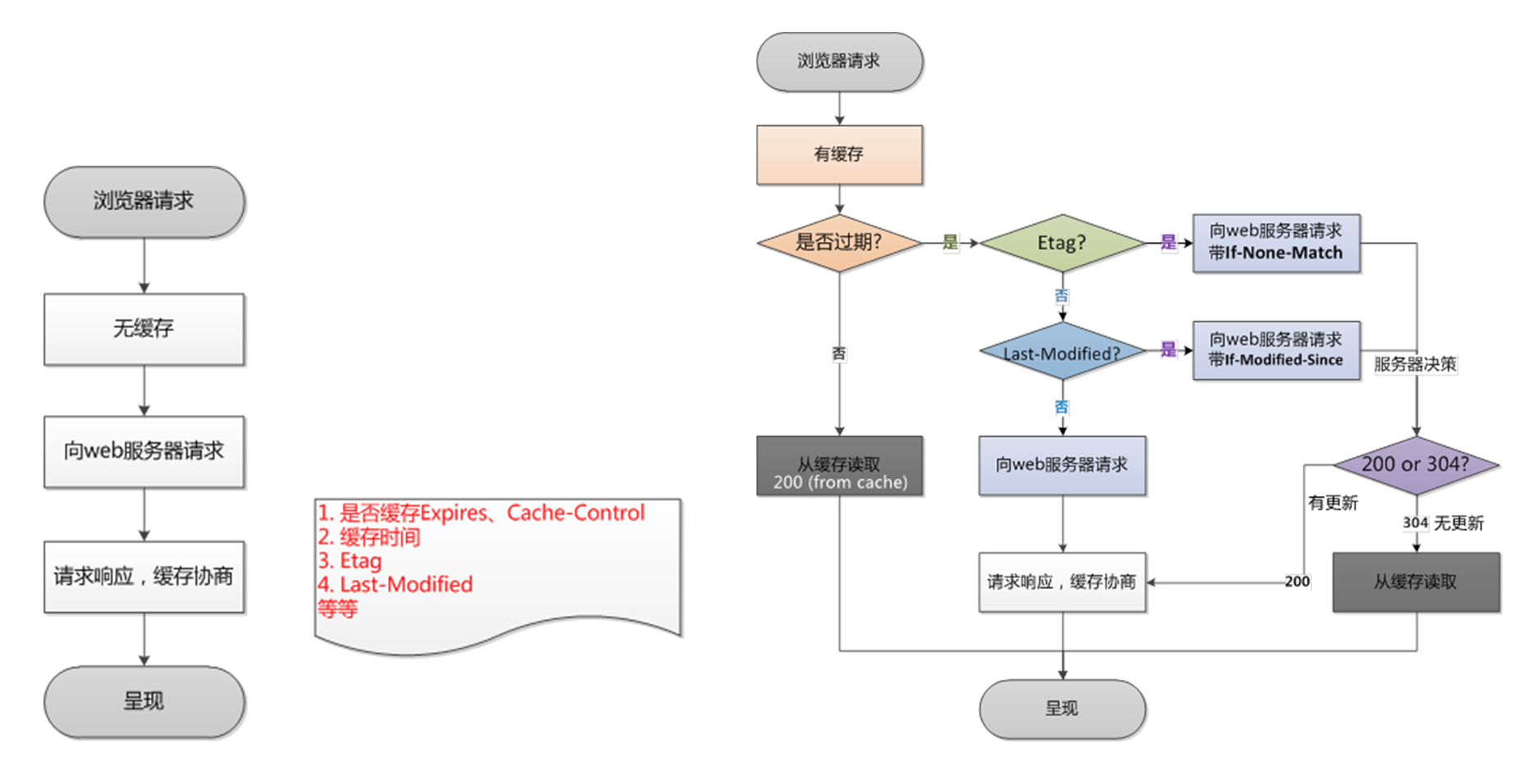
如上图所示,左图是首次加载,浏览器并没有做任何的缓存;右图则是再次访问的时候,一般已经存在缓存了,因此需要判断是否需要更新缓存。
判断缓存是否过期
Expires和Cache-control都提供缓存是否过期的判断,不过前者出现的时机更早,兼容 HTTP 1.0;后者是前者的进化版,具备更加精细的控制选项,支持 HTTP 1.1。在实际开发中,Cache-control的优先级和重要性要大得多。当通过这两个 HTTP 头判断出缓存已经过期,则进入下一步Etag/If-None-MatchEtag是资源在服务器上的唯一标识,一般在资源变动的时候由服务器自动分配。浏览器发现过期的缓存带有Etag,则将会向服务器发送带有If-None-Match的请求(就是Etag的值),服务器收到请求后会比较最新资源的Etag是否一致,并依此返回 200 或 304Last-Modified/If-Modified-Since
同理,浏览器发现过期的换粗带有Last-Modified时也会向服务器发送一个携带该值的请求,服务器同样是比较最新资源的修改时间并返回 200 或 304
Etag和Last-Modified一般不会同时出现,因为这会增加服务器配置的难度。通常而言,Etag验证的优先级会更高,同时对资源的版本控制会更强。服务器返回 200 状态码其实是告诉浏览器缓存过期了,需要重新下载。而 304 则是告诉浏览器缓存依然可以使用
但其实我们在实际的开发中,基本都是使用永久缓存更新机制——设置超长有效期的 Cache-control,这样浏览器永远也不会进入询问缓存是否有效这个阶段(即使是 304 也还是需要一次请求),转而使用更改资源引用路径的方式来强制更新资源,换句话说,如果一个脚本的引用名称没有改变(每次更新使用自动化给脚本增加一段唯一标识符 MD5),它就是永久有效的。这种更新与利用缓存的机制,可以大大地提高资源的利用率,并且减小来服务器的压力,是现代 Web 应用的常用手段。
最后推荐一个知乎的回答:大公司里怎样开发和部署前端代码?
高票答案 @张云龙 其实非常形象生动地讲解了前端更新部署的流程,包括其原理和进化史
客户端部分
客户端部分的优化其实相对而言,不像网络优化那样具备特别明显的提升,不过在现如今越来越注重用户体验的趋势下,客户端的流畅度也是一个产品质量的绝对考量指标之一。
图片裁剪技术
我们第一个需要关注的对象是图片的裁剪,之所以关注这个,是因为在主题系统或者 DDYQ 中,其中的图片均是由用户自行上传的,虽然我们提供了建议尺寸,但是还是发现在很多不需要大图的地方,用户还是使用了超高分辨率的图片(比如头像)。因此减小图片的尺寸将有效减轻服务器压力和加速页面渲染,这里听起来好像是服务端需要做的事情,但是前面提到,我们是使用了 CDN 网络的,因此图片存储其实是由 CDN 提供商负责的,如七牛云存储,他们提供了 图片压缩的功能
瀑布流的秘密
我们都使用过微博,不管在客户端还是在网页版本,只要你希望看到更多,你可以一直往下滚动,查到到好友们源源不断的动态。这种体验非常好的设计就叫做 瀑布流。在没有对这种设计做出深入理解以前,你可能很难理解实现 瀑布流 是一件非常需要技术的事情,我在经历了两次 瀑布流 性能优化以后(一次是 初礼电商移动版本的首页,一次是 DDYQ 的首页),虽然这两个由于功能实现其实是不一样的,不过还是让我吃到了各自的苦头
资源加载问题
第一个需要面对的是,资源如何加载。初礼刚开始是使用 Liquid 进行缓存输出的,很多人也会觉得直接用 HTMl 输出不是个问题。那么这里需要考虑你服务器的负载条件和瀑布的长度了。使用 HTML 直出几十个微博动态,那么也许是个好主意,但是如果像初礼那样,把整个店铺的上千个商品都塞到首页瀑布中,相信我,你不会想着去访问的。这将耗费你几十兆的流量,加载了愈千个图片!考虑网络的因素和服务器的压力,我们最后使用了 Ajax 动态加载商品,一次只加载二十个,浏览到底部再加载二十个,依此类推。同时也用到了前面所说的图像裁剪策略(为节省流量和提高网速甚至抛弃了 Retina 屏幕),不仅如此,后台甚至还专门提供了一套 API,获取商品信息时可以只获取常用数据(JSON 大小只是完整版本的约三分之一)
- 网页流畅度问题
如果放在十年前,我想这个问题肯定会特别严重,不幸的是,即使现在智能手机性能和浏览器效率都如此之高的现在,在加载了超长的瀑布流之后,浏览器的运行流畅度也遭遇了考验。
首先是滚动卡顿的问题,我们在一个 DIV 中放置了瀑布流,那么在移动设备中会出现一定的卡顿,这是因为移动浏览器需要同时判断内部滚动条和外部滚动条以及滚动回弹。
解决方法是在给该 DIV 加上一个属性 -webkit-overflow-scrolling : touch,这样系统会认为这里需要弹性滚动(手指滑动速度越快,滚动越快,感受起来更流畅更像原生 app),会充分利用硬件加速的优势,代价是付出更高的内存消耗,不过考虑到整个瀑布流一般只需要一个外框,所以内存一般是可以接受的
其次是内存泄露的问题,可能很不可思议,但瀑布流确确实实有可能导致内存泄露,最终导致整个页面瘫痪,这是血的教训!
有一次客户向我们反馈,用户在某些情况下页面会卡住。他在打开页面后可以正常使用,但如果这时接到一个电话(或其他 APP 的操作),再回来查看页面,就发现页面完全不可交互了。后来我们发现,他使用了国产品牌比较老旧的一款智能手机,系统内存非常有限,因此在打开页面时基本消耗了系统大部分的内存,而切换多任务的时候,系统把这部分内存释放给了其他应用。因此再回来页面后就会卡死。
解决这个问题花费了不少心机,在动态加载后,我们还加上了 DOM 优化。其实道理很简单,页面 DOM 中的每一个标签,都是一个非常庞大的 DOM 对象。我们常说 DOM 操作是很费性能的,其实不被操作的 DOM 本身就很耗费性能,因此想办法减少 DOM 本身存在就是一种优化策略:优化 DOM 结构,减少标签嵌套和标签属性都有利于性能。这里我们参考手机淘宝,把 <img> 标签全部干掉了,取而代之将图片作为背景图片放置在包裹元素上达到同样的视觉效果。我觉得这是最简单适用的优化方式,在这次事件后我写代码非常注意不要出现无意义的嵌套和冗余的标签,因为这也是作为一名前端工程师的职业素养:做到极致,而不是被逼到极致
另外还有一个更激进的优化方法(鉴于难度成本和瀑布流长度,也考虑目标用户的机器性能,我们并没有实际应用):适当回收不需要使用的 DOM。比如一个瀑布流完全加载后有一万条咨询,那么用户实际看到的部分可能只有不到一百条,将一万个塞到 DOM 中是没有意义的,而且及其耗费内存,那么我们可以将用户正在浏览的一百条以外的内容的 DOM “删除”——转将关键数据而存储到一个 JS 数组中(JS 数组的内存和 CPU 开销远远小于 DOM),然后监听用户的操作行为如滚动,在需要的时候进行替换。
FastClick
在手机浏览器中,有一个双击放大的功能。但是浏览器其实并没有办法真实地知道你是单纯的点击还是要进行双击操作,因此会在第一次点击后等待约 300ms,如果在这时间内又捕捉到了一次点击则判断为双击。因此在移动端其实可以认为没有 click 事件,取而代之的是 tap 事件,这种体验问题也叫做 tap 穿透
因此这实际上是一件非常影响体验的事情:你每次点击一次屏幕,感觉都会出现延迟(让人感觉性能不好)!解决这个问题最好的办法一般是引入下面这个库
FastClick
其实 iOS 10 更新中的 Safari 和最新的 Chrome 中已经解决了这个体验问题,双击不再是放大了。
FastClick采取的解决方案其实是监听touchstart、touchend和touchmove,并根据它们的关联来对用户行为进行模拟,同时取消原有的click事件
代码分割与服务器渲染
前面其实有提到,合并多余的脚本和样式可以节省一次网络请求,在移动网络延迟如此之高的情况下(我们很难保证链接会被重用),不失为一种良好的优化策略,我们在 DDYQ 中使用来 Vue.js 作为开发框架,也就是说它是一个单页应用(SPA)
SPA 的一个好处是减小了后端的计算压力。但是完全基于 Ajax 的 前端 SPA 实现有几个问题:一是失去了 SEO,第二个是首屏渲染时间会变慢(因为一般将整个 APP 的脚本和样式都分别放在一个文件里,体积相对会大一些)。后者的原因是,浏览器对 HTML 有渐进渲染的功能,我们打开超大的网页是一点一点显示的。而通过脚本动态插入 DOM 的方式则是不可能触发渐进渲染的,因此相比之下,首页渲染时间会更长一些。
解决以上问题的方法就是,代码分割和服务器渲染:
代码分割其实我们一直在用,你看,我们在官网中总是把全局需要的东西放在首页(如 jQuery),而只有某个页面才需要的东西单独放在那个模块,这样用户访问首页的时候需要下载的脚本会相对少一些,减小来首页时间。代码分割也是这样的道理,只下载首页需要的脚本或资源,而把其它页面的资源做成单独的资源(可能做成延迟加载)
服务器渲染更多是解决 SEO 的问题,我们官网的源码其实是基于 haml(方便管理修改),需要引擎编译一边输出 HTML(通常缓存 HTML),不过遗憾的是,除此之外我对服务器渲染所知甚少,因为 DDYQ 这种应用既不需要考虑 SEO,同时体量也较小,代码分割和服务器渲染均不是一件节省成本且必要的事情
结语
对于 Web 性能的方面的研究,我所知甚少,尤其是对于后端方面几乎可以是零认知。如果有机会,我希望可以学习到性能监控和流量跟踪,压力测试和负载均衡等等,这些很难在具体某本书籍中看到,更多的是一个团队的实战经验,也需要实际的项目磨练。
不过对于入门 Web 性能,我觉得以下几本书是很值得推荐的:
尤其是最后一本,谈及了许多基于 HTTP 层面的优化和原理,对于现代互联网 Web 开发是颇有裨益的,因为随着 CPU 的日益强大(即使是移动端,也有高通835和苹果A10这种性能怪兽),客户端的性能优化对体验的提升其实是相对比较小的,尤其是对于移动轻应用而言。虽然网络能力也随着 4G网络日渐强大,但无线网络始终还是受限于复杂的干扰和手机省电的原因拥有较高的延迟和丢包。因此在 HTTP 2.0 全面普及之前,我觉得还是有必要着重从网络入手谈性能。